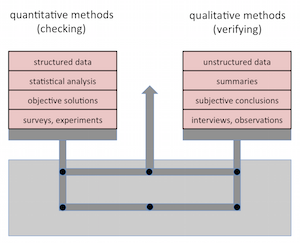
Qualitative Verfahren erzeugen nur Informationen zum jeweils betrachteten Fall, und generelle Schlussfolgerungen darüber hinaus sind Hypothesen. Quantitative Verfahren bezwecken eine systematische empirische Untersuchung beobachteter Vorkommnisse. In der Compliance werden quantitative Verfahren üblicherweise angewendet um regelmässig die Kundenbasis zu untersuchen. Das Resultat sind Hypothesen zu bestimmten Risiken, die durch qualitative Verfahren im jeweiligen Fall falsifiziert werden können.
Personennamen werden verwendet um Individuen zu unterscheiden. In der heutigen digitalisierten Welt, ist die Schreibweise von Namen wichtig, da Computer Namen Letter für Buchstabe um Buchstabe abgleichen, sofern nicht technisch ausgereifte Namensabgleich-Software verwendet wird. Eine gründliche Betrachtung des Problems der Namensgebung ist jedoch schon hier möglich.
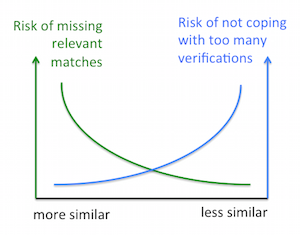
Compliance benötigt Namensabgleich-Lösungen: Beispielsweise um Kunden- mit Sanktions- und PEP-Listen zu vergleichen. Unglücklicherweise kann es für den Namen einer Person viele Schreibweisen geben (z.B. verschiedene Transliterationen). Darum muss ein Entscheid gefällt werden ob nur sehr ähnliche Namen oder auch weniger ähnliche Namen überprüft werden sollen. Im ersten Fall verpasst man möglicherweise relevante Treffer, und im zweiten erhält man in der Regel zu viele Treffer.
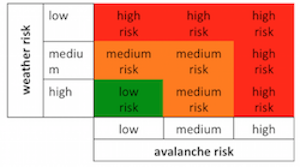
Die Empfehlungen der Financial Action Task Force (FATF) und der Anti-Money Laundering Act (AMLA) fordern einen risikobasierten Ansatz. Im Folgenden werden einige grundlegende Aspekte von risikobasierten Ansätzen diskutiert.
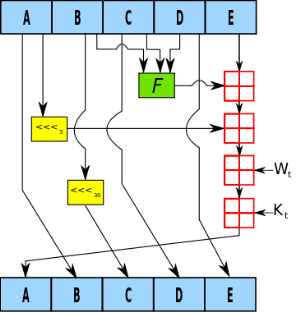
Hash-Funktionen wie zum Beispiel SHA-1 sind im Digitalgeschäft wichtig um kleine Textstücke (ein Digest) aus grösseren Dokumenten zu machen. Dieser Digest ist dann ein einzigartiger Stellvertreter für dieses Dokument. Keine zwei Dokumente sollten den gleichen Digest haben.
